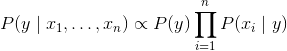EECS 349 Machine Learning Project on
San Francisco Crime Classification
Bo Guan, Panitan Wongse-ammat, Xinyuan Zhao
Email: {BoGuan2015, Top, xinyuanzhao2016}@u.northwestern.edu
Northwestern University
Naive Bayes
Naive Bayes is one of the most efficient and effective inductive learning algorithms for machine learning and data mining. We found that Naive Bayes was critical due to its output being a probability. Given a class variable y and a dependent feature vector x1 through xn, Bayes’ theorem states the following relationship:
Using the naive independence assumption, for all i, this relationship is simplified to
Since is constant given the input, we can use the following classification rule:
So that,
The different naive Bayes classifiers differ mainly by the assumptions they make regarding the distribution of . There are GaussianNB, MultinomialNB and BernoulliNB. The accuracy results of these Naive Bayes by Weka are shown in Table 3. And the training and testing results by Python are shown in Table 4.
Table 3: 10 cross-validation accuracy tested by Weka
Table 4: Accuracy and logloss results tested by Python
From the results by Weka and Python, the BernoulliNB performs better than MultinomialNB. Our final choice of Naive Bayes was GaussianNB, where the probability of the features is assumed to be Gaussian: