
EECS 349 Machine Learning Project on
San Francisco Crime Classification
Bo Guan, Panitan Wongse-ammat, Xinyuan Zhao
Email: {BoGuan2015, Top, xinyuanzhao2016}@u.northwestern.edu
Northwestern University
Algorithm and Evaluation

To participate in the Kaggle competition for SF crime classification, each participant is evaluated on the multi-class logarithmic loss. Each incident is labeled with one true class, and for each of them we must submit a set of predicted probabilities (one for every class). We will find the log loss based on the equation written above. In the equation, N is the number of cases in the test set, M is the number of class labels, log is the natural logarithm, yij is 1 if observation i is in class j and 0 otherwise, and pij is the predicted probability that observation i belongs to class j.
For this reason, we need to find an algorithm that can classify each incident and give us probabilities for each class. After doing more research and taking Professor’s suggestions into serious consideration, we test some algorithms such as Naive Bayes, k-Nearest Neighbor, Logistic Regression and Random Forest. Those algorithms are critical because they are able to generate their probability outputs for each class to compute logloss. We ran these algorithms and validated them with 10-fold cross validation in Weka. Their results are shown in Table 1.
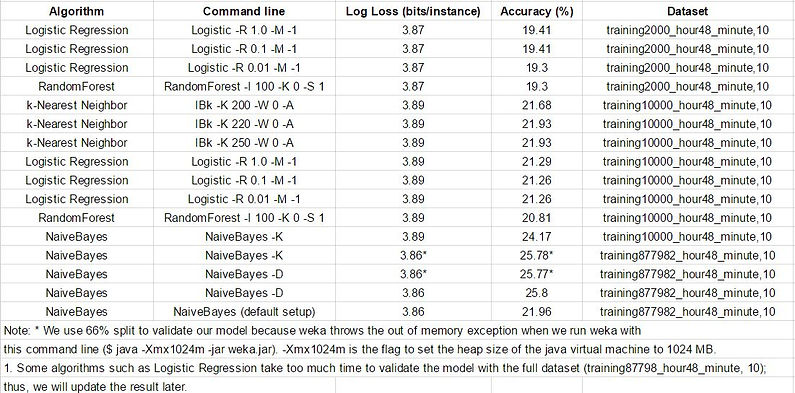
Table 1: The results of the classification algorithms we have tested in weka
We use the scikit learn package to write python scripts, and we customize these algorithms to have a better result. We will discuss how we customize each algorithm and its result in the section below.